-
Type:
Improvement
-
Status: Resolved
-
Priority:
 Minor
Minor
-
Resolution: Fixed
-
Affects Version/s: 10.10
-
Component/s: Streams
-
Epic Link:
-
Tags:
-
Sprint:nxplatform 11.1.11
-
Story Points:3
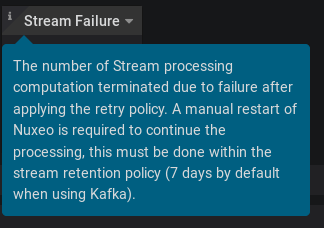
Since NXP-27164 there is a probe to report stream processor failure. Because probes are used through the runningstatus as health status, the result is that a record that creates a systematic error on the processing will block the entire system.
This can be mitigated by using proper retry policy for a temporary failure (service unavailable or in failure that requires human intervention) but this is problematic for a buggy record that creates a systematic error.
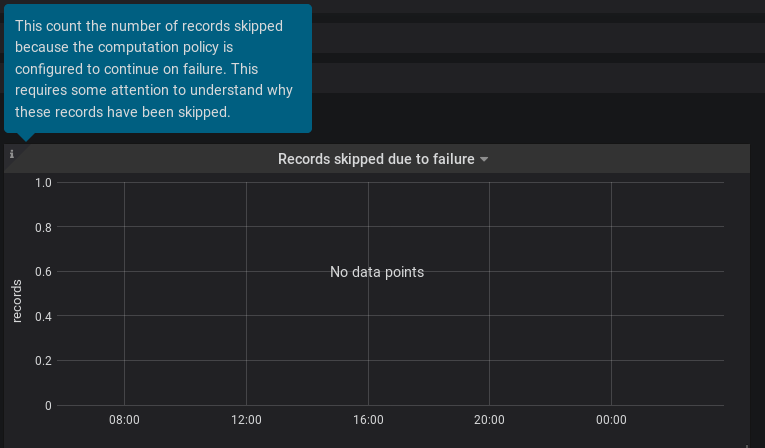
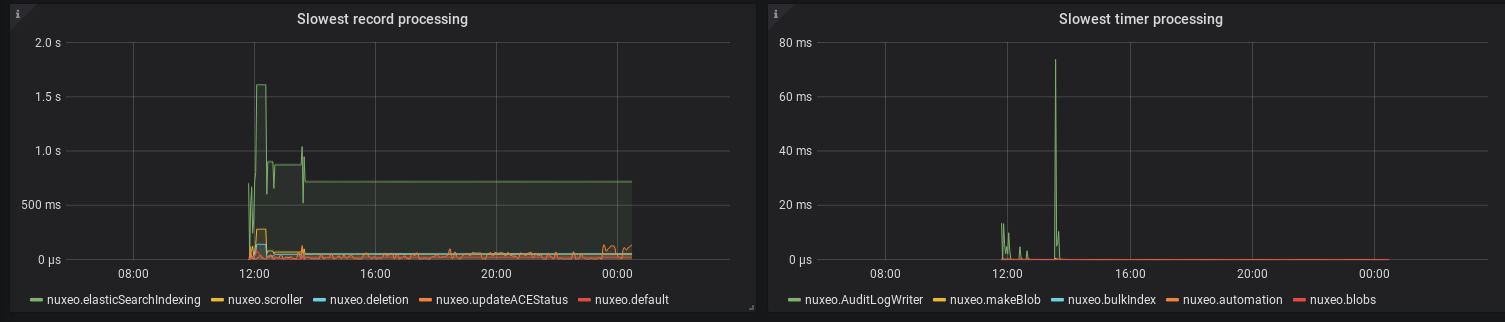
So instead of activating a probe for the stream processor, we could have metrics on processing in error that can be used as a warning in a monitoring dashboard.
This way the ops can choose when to restart Nuxeo node instead of having them automatically blacklisted or restarted.
The solution is to expose a counter metric when the processing enters in termination due to error, also even if the probe is disabled it will be nice to have the stream processor probe output to list which processing is failing.


- depends on
-
NXP-27525 Disabling healthCheck probe does not work
-
- Resolved
-
- is related to
-
-
- Resolved
-
-
NXP-28043 Backport Stream Processor probe to the runningstatus
-

- Resolved
-
-
NXDOC-1936 Add a Nuxeo Stream section about error handling
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-

